OctoDOC document format
Octodoc Document is XML-based file format that combines vector and raster graphics with structure information. There are four different elements at the document root level: dictionary, design, data and resources. In current implementation there is one of each but in future versions the document could store multiple alternative designs, for example paginated and mobile view of the same document can be stored in single file.
The dictionary type appears under root but can also be encountered as part of other nested items like fragments and fields. The purpose of the dictionary element is to store arbitrary meta-data along with the document. Values in dictionary are named entities that may contain a value or another dictionary. Nesting allows creating custom namespaces for storing complex structures. In simplest case the dictionary may store name of author, change date or notes but it is also possible to accommodate additional processing rules for workflows, rendering options etc.
The design element contains graphical parts of the document. The main building block of a document design is called fragment. Fragments can be used as pages, invoice rows, table cells or as containers for other fragments. Container fragments have optional layout rules attached which instruct formatting engine how to set up the placement of elements during layout process.
Document has optional data fork that declares tree of nested data items. Each item in the data DOM has a name, type and value. The structure of the data tree defines the data interface of a document. Content of data DOM can be imported and exported as XML or JSON and it exists independent of the document graphics. The data items can be optionally bound to the fields in document, so the data DOM serves as data source for presentation. Not all items in the data DOM need to be bond to presentation fields, so the DOM may store more complex structure than is necessary for presentation. Same applies to the variable fields in layout, some presented values may be calculated during runtime, modified by script or serve as user input areas.
The document resource element stores images, scripts and fonts. Resources may be stored in file as embedded streams or as a reference to the external file.
Most of the elements in the DOM have the name attribute. The value of name is string of characters with some syntax restrictions. Most notably, there cannot be whitespace in name and the name must not start with a numeric characters. This is necessary as we want to allow element access from JavaScript and have the name usable as an entity in documents internal path specification. User interface reports error when spaces and other unsupported characters are used in name.
The info property usually appears along with name and can be used as free text description of the element. Both name and info are optional values, except in the data fork where the name must be set on each item element. Note that extended information can be stored in document dictionaries.
Fragment
Fragment elements serve as the building blocks for layout. In the current implementation, other types of content – such as paths, rectangles, or images – do not participate in the layout, so they need to be wrapped in a containing fragment.
A dynamic layout can be implemented by specifying data binding on the child fragment and setting the layout method on the container fragment3. When the data model is populated with multiple instances of a source data item (e.g., invoice rows), the content populator will also instantiate multiple copies of fragments.
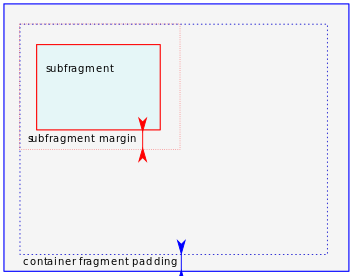
A fragment element has margins and padding – properties that add extra space during the layout process, either to the outside of the fragment (margin) or to the content (padding)5. The padding of the parent fragment and the margin of the child fragment are combined to calculate the actual position in the layout.
Layout
Fragment containing multiple sub-fragments can have static layout in which case all of its content retains the positions assigned at design time. In order to accommodate dynamically populated content, the parent fragment needs to have non-static layout type. The containing fragment(s) need to have a Repetition property set. In the document XML the setting is stored as follows:
<instances repeat="true" def="1" min="1" />
Currently implemented layout methods are:
- Vertical stacked
- Horizontal stacked
- Vertical wrapped
- Horizontal wrapped
In current version, the direction of layout is presented as choice between horizontal and vertical. The model however defines the direction internally as alignment, so in future releases it will be possible to specify right-to-left horizontal or bottom-to-top vertical layout.
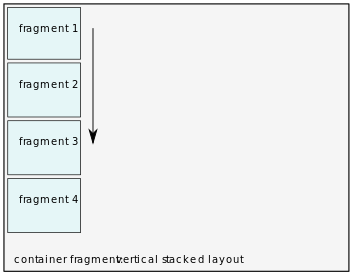
Vertical Stack fills available space with content from top to bottom.
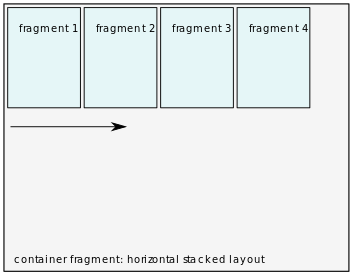
Horizontal stacking fills available space with content from left to right.
Vertical wrapper fills available space with content from top to bottom and when running out of space, creates another column.
Horizontal wrapper fills available space with content from left to right and when running out of space, creates new row.
Note that the layouts may be nested – the child fragment can itself be a container of other fragments. For instance, vertically wrapped fragments (rows) may have horizontal stacked layout, so their child elements are treated as cells in a row.
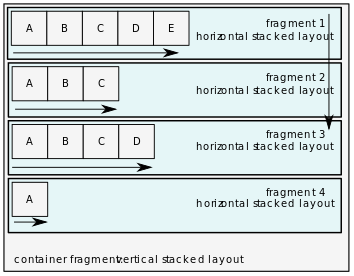
The layout settings can be applied to all fragments and there is “Layout direction” setting also on the node of the document. The layout of this top-level node may not be used in all scenarios. When the document is processed for printing, the topmost is treated as page and the level layout is simply not applicable.
Overflow
When layout fills the container area completely, the overflow event occurs. Without specific handling, the overflow simply causes the content to run out of the area. To resolve the overflow, the layout engine needs to be told which method to apply.
When the overflow is set to “Repeat page”, the layout algorithm looks up the topmost fragment at overflow site and duplicates that fragment. The overflowing content will be detached from its container and moved into the newly created instance of top container. This type of overflow always duplicates the topmost fragment with all its content, except the part where the overflow occurred. New instance is inserted right after the original, so the layout process will re-process this copy when it moves downstream in document structure. When overflow occurs in this new copy, the duplication and content carry-over is repeated until there is no more overflow.
When the overflow is set to “Specified target”, the layout algorithm looks up the template for new fragment by its path. The continuation fragment is expected to be downstream (after the overflow site). The overflow content (child fragments not fitting into area) will be detached from the current parent and moved into new container. This method allows setting up the title page with different design than continuation pages.
Document path syntax
The data binding is used to make connections between elements in a document, for instance the items in data tree can be bound to fields, the overflow target is defined as path to another fragment.
The document structure in XML resembles a file directory tree with folders (fragments) and files (fields, shapes). Each element type has a unique element tag in XML tree – that name is not changeable. Many elements have also a ‘name’ property which can be assigned by user. Element path can use either the XML tag name or the name property when referring to an element.
Following example is simple document that has contact structure with single item ´person´. The value on the data item is already set here but note that in merge process the data DOM values are usually populated from external XML or JSON message.
<?xml version="1.0" encoding="utf-8"?>
<document format="0.9">
<design>
<fragment size="210mm,297mm">
<label position="43.2pt,39.6pt" size="194.4pt,12pt">
<text>
<font />
<fill color="gray 0" />
<paragraph>
<run>Dear </run>
<span>
<field binding="/document/data[0]/$contact/$person" />
<run>person</run>
</span>
</paragraph>
</text>
</label>
</fragment>
</design>
<data>
<item name="contact">
<item name="person">John Smith</item>
</item>
</data>
</document>
The path “/document/data[0]/$contact/$person” is a sequence of navigation commands:
- document selects DOM root element
- data[0] selects first element with tag data, the number in square brackets is the zero-based index of the element
- $contact selects child element from data node that has name attribute value “contact”
- $person points to the named child of $contact element
Using only the indices and XML tags, the same path could be presented as: “/document/data[0]/item[0]/item[0]”